Code management
A software development project of any significant size will include many individual files, typically arranged in a folder hierarchy. The correct operation of the system will depend on two major factors:
- The files being in their expected locations
- The files being consistent in the sense that they do not conflict with each other
Structure
The first factor is not usually a problem in a project where there is only one developer. That person makes appropriate decisions about the arrangement of files, and then sticks to the plan. There can sometimes be an issue when deploying an application to a server either for testing or for release. The folder hierarchy will be the same but the root directory is often different. To resolve this, the differences need to be identified and appropriate references updated. A more serious issue can arise if the developer has mistakenly used absolute path names when referencing files in code. This will almost certainly cause errors on deployment and should be avoided. The correct approach is to make file references relative to the application root folder. There are a few other guidelines that can be followed to avoid deployment errors, such as making sure that all filenames are lowercase, and do not contain spaces. Most of these things are simply a matter of attention to detail.
The problem is more complex when several people need to work on the same set of files. This is almost always the case in an agile project. Left to make their own decisions, it is likely that each developer will make slightly different choices about filenames, folder structures, and so on. In a team, these things need to be standardised so that everyone is working to the same conventions. Using default structures as much as possible can be a good strategy - many technical environments come with a recommended set of rules, and it is just a question of following the installation instructions. Often, it is a good idea to make the folder structure reflect the architecture of your application. For example, an application that uses the Model-View-Controller pattern might have a separate folder under the root directory for each of the three types of component. Once these decisions are made, it should not be difficult to get all of the development team to stick to the rules.
Consistency
The second factor is actually the more difficult problem. That is because in an agile project one file may need to be modified many times by different developers. Although each developer may do their tasks thoroughly including unit testing their changes, bugs can still arise when modified code is integrated into the shared codebase. The following scenario illustrates the issue.
In the online widget system, a widget is defined with the following class declaration:
1 2 3 | |
Alice starts to work on a task to add different sizes of widget. She update the user interface and also adds another parameter to the widget constructor:
1 2 3 4 | |
Meanwhile, Bob has started to work on another feature request to make the widget ordering application multilingual. As part of that task, each widget needs to be associated with a default language. As well as changes to the interface, this also requires a change to the widget constructor:
1 2 3 4 | |
Now there are two new versions of the Widget class, each with two parameters to the constructor. When Alice and Bob test their code independently, everything works perfectly. If they both check their code in, however, errors will occur. Whoever checks in their code last will overwrite the version of the Widget class with their version. If that is Alice, there will be errors when Bob's code is run. One reason is that Bob's code expects the second parameter to be a string variable, while the widget constructor now defines it as an integer.
This simple example shows that when working in a team, it is vital to track changes to the codebase that occur in parallel and to carefully merge the changes back together so that the final version is complete and consistent. This process is commonly known as version control, and there are several technologies available to implement it. One of the most popular is called git, which provides a set of management functions for maintaining a series of snapshots of the codebase and their dependencies. Cloud services such as GitHub and BitBucket provide simple interfaces for using git, although a local git repository can also be created.
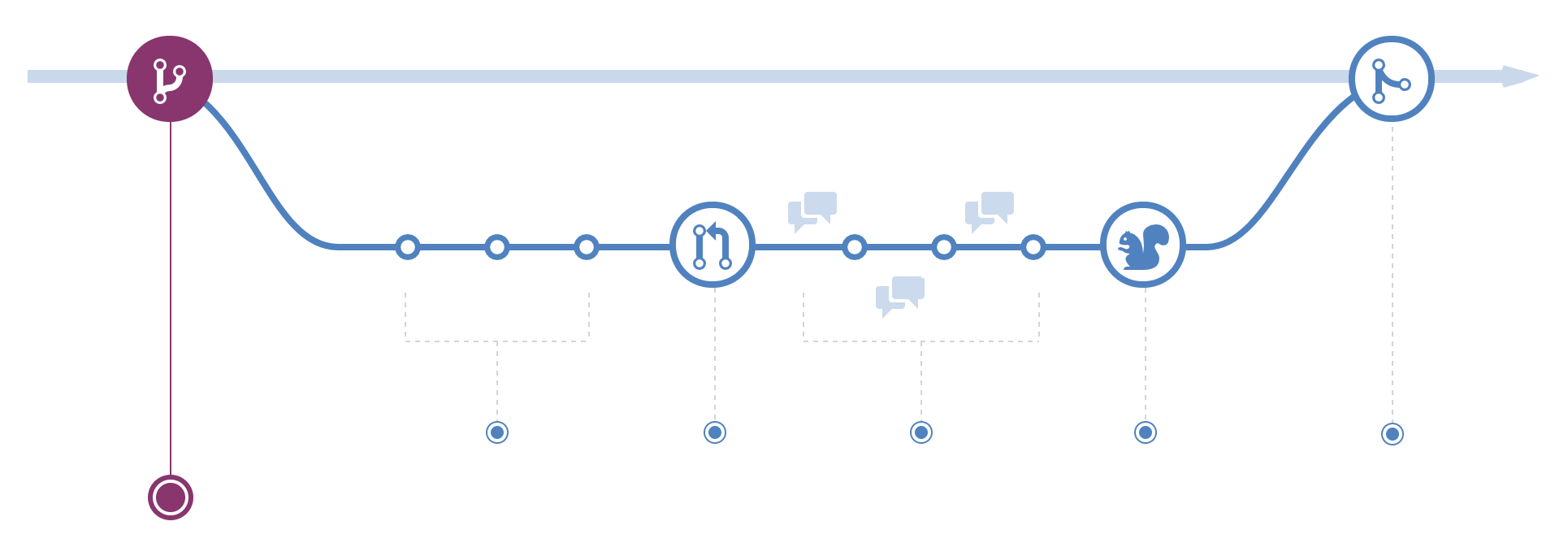
There are several workflows that a team could decide to use in order to coordinate their development activity. The one illustrated in the image above is the forking workflow in which every change is given its own branch and then changes are carefully merged back into the main branch (usually called the master) once they have been approved. This workflow is often used for open source projects where the contributors are not necessarily known to each other and care is required to maintain the quality of the development.
Another workflow that is suitable for small teams who all know each other's capabilities is the centralized workflow in which each member of the team clones the main branch, makes changes locally, and commits those changes when they have been tested. Git prevents changes being committed if there are conflicts with the master. It is then the developer's responsibility to copy any recent changes into their personal repository (known as rebasing) and resolve any conflicts before committing again.
Using GitHub well takes practice, and the best way to get started is to study the documentation provided - there are some links in the Further Reading list below.
Refactoring
When a file is first created, the developer is usually careful to give it a good structure and to use appropriate naming conventions so that the code is as readable as possible. As changes accumulate though, the initial elegance of the code can start to deteriorate. This is often because a developer usually avoids making modifications to a piece of code unless absolutely necessary. This precautionary principle is good in the sense that the fewer changes, the less likely it is that bugs will occur. However, it can also mean that the solution chosen is not the optimal one, and that instead of rewriting a method in a clear way, for example, the developer might leave the original method as it is and introduce a second method that does a similar job specifically to handle a special case. This introduces some redundancy into the code, violating the DRY principle (Don't Repeat Yourself). Over time, many such modifications can start to make the code difficult to understand and maintain.
Refactoring is the activity of rewriting existing code to eliminate redundancy, improve efficiency and enhance its maintainability. Merging changes into the master branch is an opportunity to refactor the code.
 GitHub Guides
GitHub Guides