Integrated testing
Waterfall-style project methodologies typically have a testing phase towards the end of the schedule. The idea is that the development team construct the software and then when it is ready, they show it to the customer. The problem with this is that the development may takes several months - if not years. During that time, any number of misconceptions may become permanent features of the software. By the time the customer sees the application, correcting those misconception may involve many days of reworking the code and retesting. Leaving testing until the end can thus be very expensive.
This is a simplistic view of the waterfall approach, of course, and some testing obviously takes place before the main user testing phase. However, it is also true that testing is one of the aspects of code development that is often done poorly and in some cases overlooked completely. For the developer, it is much more interesting to move onto the next exciting feature than to spend a long time comprehensively ensuring that their current changes do what they are supposed to do. The code will go through several more changes anyway, so why put all of that effort into testing this particular version? That line of thinking though just leads to the cartoon version of the waterfall approach where testing late in the project might reveal issues that could have been fixed cheaply earlier, but will now cost significant time and effort.
Agile methodologies insist that testing and development proceed in parallel throughout the project. The idea is that if the software is under constant test, bugs and design errors will be identified at the earliest opportunity, and fixing them will be straightforward. This approach is embedded in several of the principles in the Agile Manifesto.
What is a test?
It sounds simple enough, but like any other term that is used in everyday language, it is worth taking a moment to be precise about what we mean. A test compares the actual behaviour of a piece of software with the expected behaviour. If they are the same the test succeeds, and if the actual behaviour is different from the expected, the test fails. So far so good, but it is also important to be precise about how the comparison is done. Usually, a test case is defined which specifies a certain input and a certain expected output. Take for example a simple method which calculates a student's final degree classification based on their module results. First, we need to know what rules the software is implementing:
- A module is usually worth 20 credits, but there are double and triple modules
- The classification is based on the student's average mark over 180 credits
- A student must complete at least 100 level 10 credits
- A student may have a maximum of 120 level 10 credits
- The classification includes all level 10 credits and then the best results from level 9 up to the total of 180 credits
-
The classification is then awarded according to the following threshold values of the average mark:
-
70% and above: first class
- 60 - 69% : upper second class
- 50 - 59%: lower second class
- 40 - 49%: third class
- <40%: fail
In order to test our method completely, we need to identify all of the possible combinations of inputs and determine the expected output from the method in each case. In this example, the following test cases are relevant:
| Case | Expected result |
|---|---|
| Student has 100 L10 credits, 80 L9 credits and an average of 75% | First class |
| Student has 100 L10 credits, 80 L9 credits and an average of 65% | Upper second class |
| Student has 100 L10 credits, 80 L9 credits and an average of 55% | Lower second class |
| Student has 100 L10 credits, 80 L9 credits and an average of 45% | Third class |
| Student has 100 L10 credits, 80 L9 credits and an average of 35% | Fail |
We would also need to test the equivalent cases where the student has 120 level 10 credits and 60 level 9 credits which would give us 10 test cases. In addition, we need to test edge cases - ie those which fall on the border between outcomes:
| Case | Expected result |
|---|---|
| Student has 100 L10 credits, 80 L9 credits and an average of 100% | First class |
| Student has 100 L10 credits, 80 L9 credits and an average of 69.5% | First class (rounded up) |
| Student has 100 L10 credits, 80 L9 credits and an average of 0% | Fail |
Obviously, we would also need to include all of the other boundaries and credit combinations given a total of 22 test cases so far. We also need to ensure correct behaviour when some of the conditions are not satisfied. In cases like the ones below, we need to ensure that the method fails gracefully, perhaps giving an appropriate error message:
| Case | Expected result |
|---|---|
| Student has fewer than 100 credits at L10 | Error |
| Student has fewer that 180 credits overall | Error |
| Student has more than 120 L10 credits | Error |
In discussion with the customer (ie a domain expert), it may also become obvious that there are some less obvious error situations that need to be validated. For example, the method should automatically select the student's best results from level 9. We therefore need to make sure that this is the case by testing different combinations of module results. Double and triple modules count for 40 and 60 credits respectively, and must therefore be weighted appropriately in the calculation. The table below illustrates just a few examples.
| Case | Expected result |
|---|---|
| Student has the following results all at 20 credits: L10: 70, 70, 70, 70 , 70 L9: 69, 69, 69, 69, 68, 68, 68 |
First class |
| Student has the following results all at 20 credits: L10: 70, 70, 70, 70 , 70 L9: 69, 69, 69, 68, 68, 68, 68 |
Upper second class |
| Student has the following results: L10: 70 (double), 70, 70 , 70 L9: 69 (triple), 69, 68, 68, 68 |
First class |
| Student has the following results: L10: 70 (double), 70, 70 , 70 L9: 69, 69, 68 (triple) 68, 68 |
Upper second class |
Clearly the number of combinations that needs to be tested is quite large. The original developer will need to test every case when the method is first written. This is known as unit testing since it involves testing the correct operation of a single unit of code. The same tests need to be run whenever the code is modified to make sure that no errors have been introduced. In addition, it is a good idea to run the tests whenever any new pieces of code are introduced into the codebase to make sure that there are no incompatibilities with existing code. This is known as integration testing since it focuses on the interactions between pieces of code rather than the operation of a single unit in isolation. That's a lot of testing, but it is the only way to guarantee that the code works. In the words of Martin Aspeli and Philipp von Weitershausen, untested code is broken code.
Automated testing
Given the requirement to test thoroughly, often and repeatedly, it makes sense to develop automated methods for defining and running tests. Many technical environments support this type of functionality, and the examples below are taken from Python.
Essentially, a unit test in the context of a specific development
language is a piece of code that supplies a known input to a component
of the system and checks that it produces the expected output. For
example, let's assume that our classification method is called classification(),
and that it takes a structured object as a parameter which contains the
set of module results for a single module. The parameter might have the
following structure:
1 2 3 4 5 6 | |
We could then define some unit tests like this using standard Python syntax:
1 2 3 4 5 6 7 8 9 10 11 | |
The reference to self in the method definition at line 1
occurs because typically, Python tests are defined as part of a class.
At lines 2, 5 and 8, the variable results is set to a
particular set of module results. The actual tests are performed at
lines 3, 6 and 9. In each case, the method under test is called with a
particular input. The call appears as the first parameter to the assertEqual()
method whose second parameter contains the expected output. Here, we
have assumed that classification() outputs a text string,
but it could equally well output numerical values.
The method assertEqual() implements the concept of an assertion
which is a statement about the current state of a variable. In this
case, we are expecting an exact match between the output and the
expected value. Every environment that implements unit testing in this
way offers a variety of test types, and you should become familiar with
the ones in your own environment.
With this capability, testing becomes much less onerous. The initial developer can create a set of automated unit tests for the original set of test cases. These can be run as a single operation as many times as required. If a test fails, the developer identifies and fixes the problem and then simply runs the whole set of tests again. This is repeated until all of the tests are successful. If the code needs to be modified by a second developer at a later stage of the project, the set of tests can be run again to ensure that the changes have not introduced any bugs. Likewise, during integration testing, the unit tests for every component in the codebase can be run as a single operation. This ensures that everything is working as expected event though some new components have been introduced. We can therefore have confidence in the whole system.
Test driven development
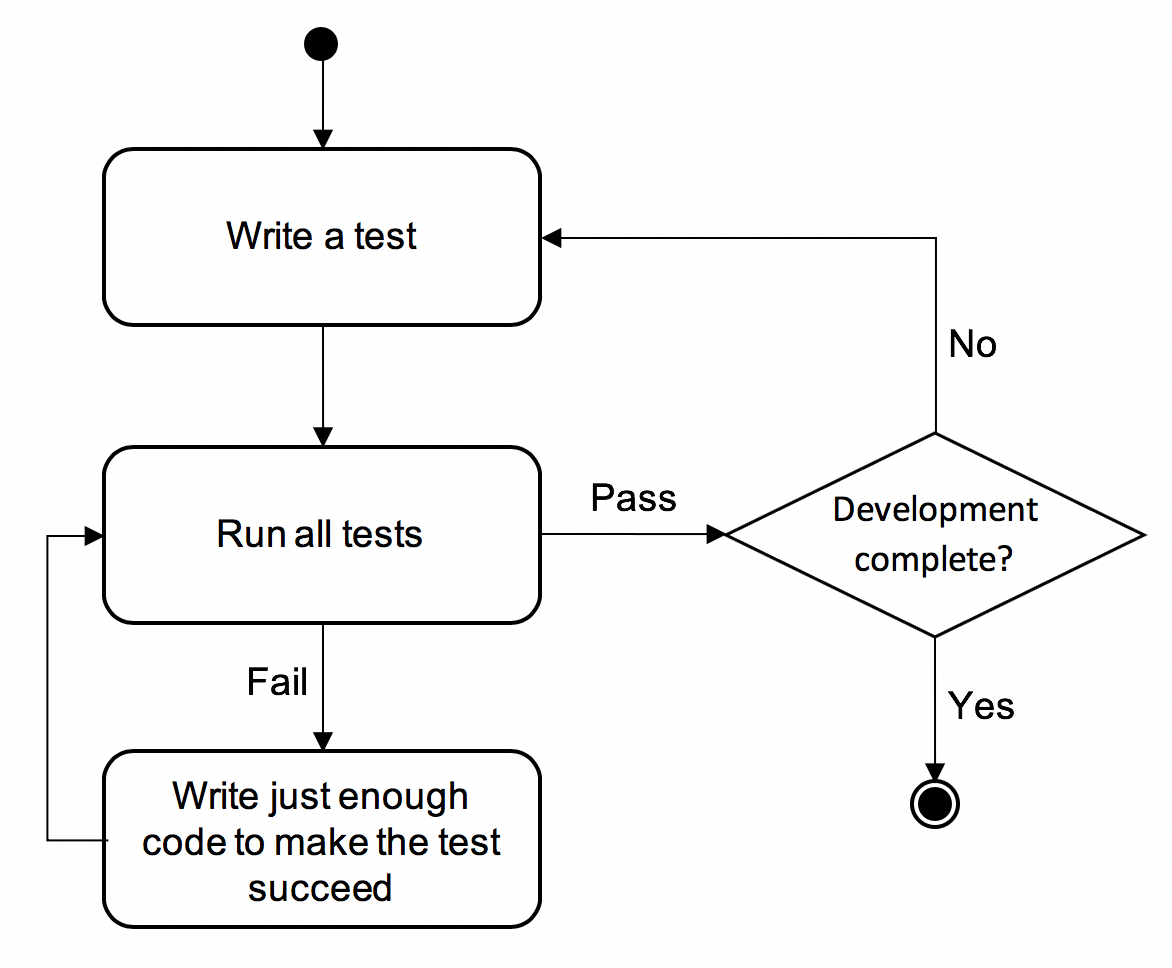
Some organisations take automated testing to the limit by requiring that a developer writes the tests before starting work on the actual code. This approach is known as test-driven development and is illustrated in the diagram below.
Further reading
 Practices for continuous testing in agile
Practices for continuous testing in agile
![]() Test Driven Development: what it is, and what it is not
Test Driven Development: what it is, and what it is not
Recommended: Find out how to write unit tests for your specific development environment