Experiment
This is probably the most common method used in computing research. It is important to recognise though that there are different kinds of experiments and each have their own characteristics. The term experiment is also used in informal language which can lead to misconceptions about its true meaning in a technical sense.
The scientific method
Science is the business of discovering new knowledge about the world. If we are talking about traditional scientific fields such as physics or chemistry, then we can use the term natural science. Science provides explanations of observed phenomena that are based on evidence rather than on speculation, fantasy, superstition, etc. It was first identified as a valuable approach in ancient Greece by Aristotle in his writings on logic.
The generally accepted structure of the scientific method is shown in Fig. 1.
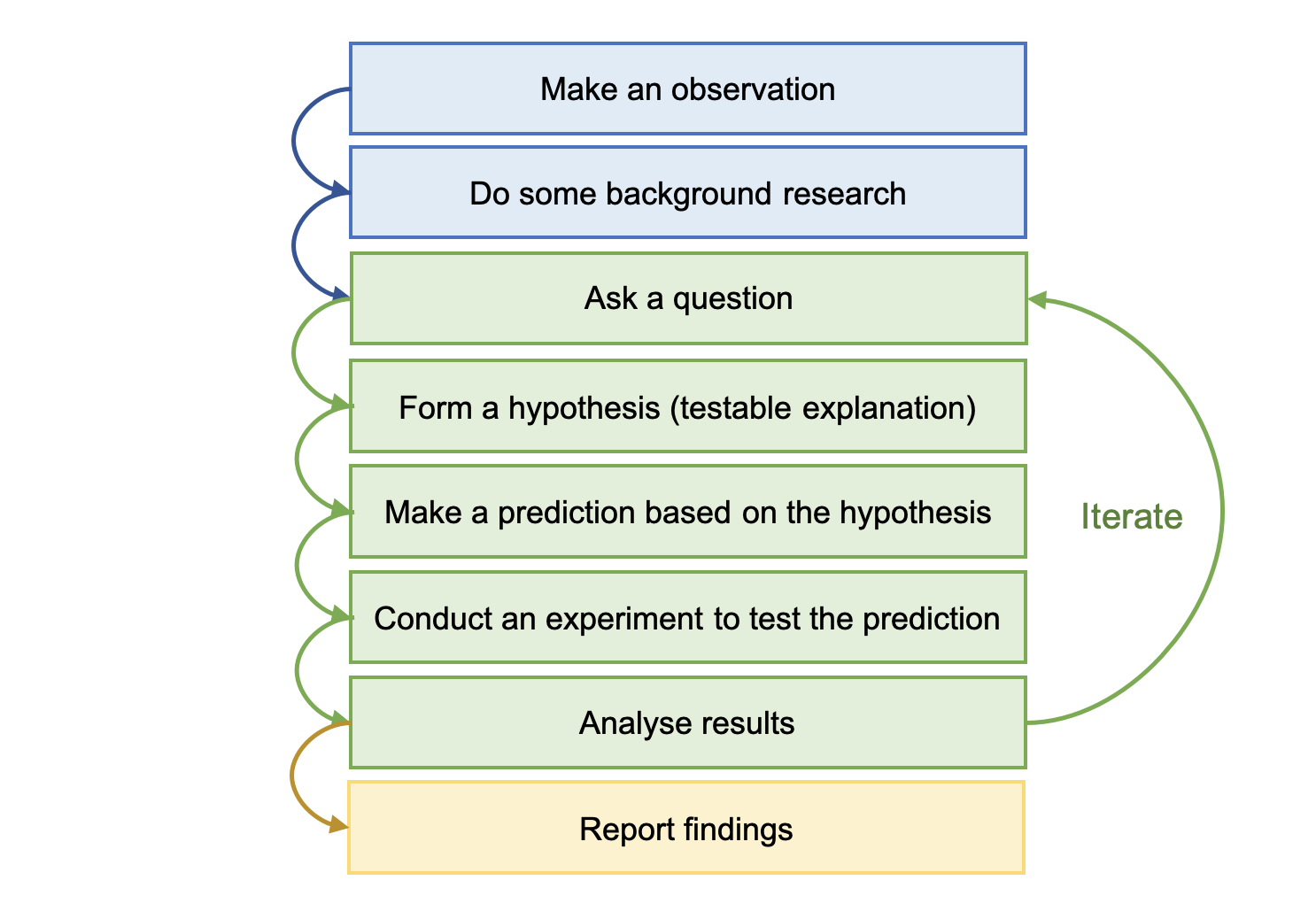
An example of the application of the scientific method comes from the discovery of the structure of DNA:
present_to_all
Question: "What is the physical structure of the DNA molecule?"
Hypothesis: It is helical
Prediction: If it is helical, its X-ray diffraction pattern will be X-shaped
Experiment: Create X-ray diffraction pattern
Results: The pattern is X-shaped; therefore, DNA has a helical structure
If the results of the experiment support the hypothesis, then it is accepted. Otherwise, the hypothesis is rejected. Accepting a hypothesis does not mean that the process is at an end and that the absolute truth is known. It just means that we have a working explanation for the observed phenomena. It is possible that later observations will not be compatible with the hypothesis in whch case it could be superseded by a different hypothesis on the basis of new experimental results.
Experimental terminology
A scientific hypothesis allows you to predict relationships between different quantities. In the case of the DNA experiment, the X-ray diffraction pattern is determined by the physical shape of the molecules in the X-ray target. The experimenter can manipulate the chemical composition of the X-ray target (the independent variable) and observe the results in the diffraction pattern (the dependent variable).
In natural science, experiments must be carefully controlled to eliminate any irrelevant factors. For example, impurities in the DNA sample might distort or obscure the diffraction pattern. If they cannot be removed, some aspect of the experimental procedure must account for them. These balancing factors are called controls. There are many online explanations of the scientific method such as this one if you would like further information.
Types of experiment in computer science
present_to_all
- Feasibility experiment
- Trial experiment
- Field experiment
- Comparison experiment
- Controlled experiment
Computing is different from natural science, but depending on the research question, an experimental approach may still be valid. Pajares (2014) identifies five different types of experiment in computer science which are described below from least to most rigorous.
1: Feasibility experiment
This type of activity might also be called a proof-of-concept study, and sets out to test whether a novel technique or technical approach can deliver the desired results. Little of the scientific terminology is applicable, but defining an experimental protocol and performance measures are important to guard against bias.
2: Trial experiment
This activity goes beyond just demonstrating feasibility and aims to evaluate a system against one or more defined criteria. It generally takes place in a lab and can make use of models in order to isolate the variables of interest. Thus, the scientific concepts of independent and dependent variables are applicable. Trial experiments can be further sub-categorised according to the nature of the system under test and the environment in which the test occurs:
- In-situ trials: real application in a real environment
- Emulation: real application in a model environment
- Benchmarking: model application in a real environment
- Simulation: model application in a model environment
3: Field experiment
In contrast to feasibility and trial experiments, a field experiment takes place outside the lab. The system is tested in a live environment - that is to say, under real-world conditions - and measured on criteria such as performance, usability attributes, or robustness. The main difficulty with this approach is that in a live environment there are many factors that are difficult to control for and therefore it is difficult to claim that a field experiement is reproducible.
4: Comparison experiment
Sometimes called horse race studies, comparison experiments set one solution against another to identify which performs better against a set of defined criteria. While this structure is conceptually simple, it is susceptible to biases such as the Pygmalion Effect in which the experimenter's prior expectations influence the results. One way to guard against this type of bias is to introduce some sort of randomisation so that the experimenter does not know whether they are testin system A or system B during any given trial.
5: Controlled experiment
This is the closest match to experiments in natural science. The controlled approach has been suggested in several domains within computing including security, software development and software engineering. Some authors argue that the increasing complexity of computer systems means that controlled experimentation is the only way to fully understand their behaviour.
Natural variation
While the goal in a controlled experiment is to eliminate unwanted factors (confounding variables) as much as possible, there is usually some practical limit to this. It may come down, for example, to the accuracy of the measurements being taken. However careful you are about your experimental protocol, one run will almost certainly give a slightly different result from the next unless you are testing a completely deterministic phenomenon.
Because of natural variations like this, an experiment should be performed many times and an average result should be extracted from the aggregate dataset. Using statistical methods is the preferred strategy here. Some statistics such as the mean (average) and to a lesser extent standard deviation are generally understood. For experiments that involve comparisons, though, these will not be enough. For example, if you observe a mean difference of 50 ms in transit time for identical packets across two different router configurations, it is not possible to say whether the difference is significant, or whether it can be accounted for natural variation. To do that, you would need to apply an appropriate statistical test to your data.
Experiments with participants
Experiments which involve taking measurements (memory footprints, timings, data complexity, etc.) are fairly straightforward and rely on quantitative data. Some experiments, however, involve collecting data from people (e.g. users, developers, project managers, etc.) usually through a questionnaire or interview process. As soon as other people are involved, it is very important to consider the ethical implications of your project. Please see the section on ethics for a discussion.
If people are involved in an experiment, the potential for confounding factors is much greater as is the level of natural variation. Experiments with people therefore need to be carefully designed. To describe this type of experiment, we will need some more terminology. The table below recaps on some terms that were introduced earlier, and adds some new ones.
| Term | Definition | Example |
|---|---|---|
| Null hypothesis | A statement that is true if any observed difference is due to natural variation | "The colour of the page background has no effect on reaction time" |
| Hypothesis | A statement of expectation | "A dark page background increases reaction time" |
| Independent variable | Quantity that can be manipulated by the experimenter | Page background colour |
| Dependent variable | Quantity that is measured by the experimenter | Reaction time |
| Test condition | Set of constraints for a particular test | Reaction time task with green background |
Test subjects can be divided up and assigned to test conditions in two basic ways. In a within-subjects design (also called a repeated-measures design), each test subject is exposed to all test conditions. In a between-subjects design, one test subject is only exposed to one test condition. Sometimes, the choice is up to the experimenter's preference, but sometimes, one type of design might be better in some way than the other. For more discussion, see Budiu (2018).
In the study suggested by the examples in the table, the experimenter might choose to test five background colours red, green, blue, black and white which represent the different test conditions. The test subjects could be randomly assigned one colour each as part of a between-subjects design. This has the benefit that the reaction time task is new to the subject in every test. On the other hand, there is the risk that some people are just better that others at reaction time tests. Randomisation should help to control for that, but we would need a large number of test subjects to smooth out any variations in ability.
Alternatively, each test subject could do the test five times, once in each of the test conditions. The benefit with this design is variation between subjects can be eliminated. That is, because the same person is performing the same task each time, any variation must be due to the difference between the test conditions. This argument holds only if the effects of doing the same reaction task multiple times can be controlled for.
The statistical test that is appropriate depends on the research design. For more details, please see the section of the notes on statistics.