DDL: Indexes
As rows are added to a table they are stored in a relatively simple list structure in the database file in chronological order. Because there is no intrinsic ordering, retrieving a subset of rows using a query means looking at every row in the table, an operation known as a full table scan. While a table is only a few hundred rows in size, this is reasonable quick, but as more rows are added, the time required to perform a full table scan can become significant and performance can drop.
Fortunately there are much more efficient ways of storing data for quick retrieval. Although the details of their implementation are largely beyond the scope of this module, a simple illustration should be enough to convey the main principle.
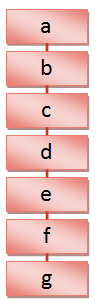
The graphic below represents seven rows in a database table, and the labels on the boxes represent the values of the primary key. If we are trying to retrieve a row using the primary key, we know that as soon as we find the value we are looking for we can stop because the primary key is unique. If we are searching for row g, we can see that starting from the top of the table we will need to perform seven comparison operations before we find it.
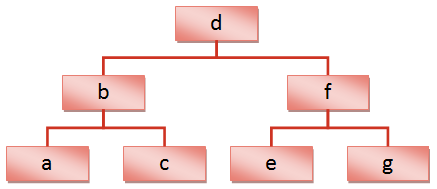
If we take that same data and rearrange it into a structure called a balanced binary tree as shown on the left, we see that the same operation will only take three comparisons. Just by changing the structure we have reduced the effort required by more than 50%.
The tree structure shown here could be used to improve the retrieval of data using the primary key, but often queries based on other columns are also common. When searching for modules in the module catalogue for example we could search by code, title or SCQF level. To execute these queries with optimum efficiency each one would require a slightly different tree structure. It is clearly not practical to maintain several copies of a table each of which is optimised for a particular query, but a less resource-hungry compromise is to maintain an optimised copy of certain columns from the table. Specifically, these would have to be columns which are known to be commonly used in queries. These parallel structures are known as indexes because they can be searched quickly and the result of the index search provides a link back to the full row in the actual table.
Most database platforms provide some indexes by default. Oracle, for example, automatically creates indexes when a PRIMARY KEY or UNIQUE constraint is defined. The database designer can define other indexes on one or more columns of a table as required. Care needs to be taken because a poorly designed index can simply take up additional space in the database without improving performance at all.
The performance of a regularly-used query can be improved by creating an index on the columns that are used to select the rows - that is to say, those used in the WHERE clause. For example, as part of a development project, we might find that student data is regularly queried using the combination of first and last names. We could create an index on the STUDENT table as shown below:
1 | |
Further detail on the use of indexes is beyond the scope of this module; however, if you are interested you can visit the Oracle documentation. The options are extensive because an index is a low-level object which depends heavily on the actual database implementation. Design of effective indexes is often the responsibility of the DBA who has the best knowledge of the physical design.
Because indexes are secondary objects - their existence depends on the existence of the related tables - they are automatically dropped when the table is dropped. If necessary, though, they can be altered and dropped independently using ALTER INDEX and DROP INDEX statements.
 Create Index
Create Index SQL CREATE INDEX Statement
SQL CREATE INDEX Statement