Normalisation
ER modelling relies primarily on the intuition of the analyst to identify “significant” entities in the environment and represent them as tables. This is clearly not an exact science, and there are lots of opportunities for error. Because relational databases are inherently mathematical, most of these errors can be identified and resolved using some simple rules. In database terminology, this process is called normalisation, because a data structure can be improved by moving through a series of normal forms. Each normal form has certain characteristics which rule out particular types of problem.
Sometimes it can be difficult to understand the need for rules, because so much can be done intuitively, and the remaining problems are minor. Think of it like learning to drive: once you have been driving for a year or two, you instinctively do the right thing at a junction or when you want to overtake the car in front. When you first start, however, you learn to apply a lot of simple procedures such as mirror-signal-manoeuvre (ask a friend about this if you don't drive yourself). Normalisation is a little like this. Once you have built up some experience, you will have an instinctive knowledge of what makes a good database structure. Until then, you need some rules to help you reach a good quality result.
Normalisation is closely related to the idea of efficiency and the elimination of redundancy. This is something that we have mentioned briefly before, but now we will concentrate more on the details. To start with, we can identify three principles of efficient database structures:
- Closely related attributes are found in the same relation (table)
- Each relation contains a minimum number of attributes
- Each attribute value is stored a minimum number of times (ideally only once)
When they are written down, general principles often sound trivial; however, there will be many occasions on which you are faced with a practical question of database design and the answer is not immediately obvious. These general principles are your first line of defence and may allow you to resolve some of those design dilemmas easily.
Normalisation is also related to the idea of data integrity. Whatever the nature of the data being stored, it is
important that it is correct, and that all relationships are correctly maintained. Because the job of designing
database is very different from the later use of that database, there are certain types of structural error that
are not obvious when you are only dealing with small amounts of test data. The rules of normalisation help you to
avoid those errors, and to produce database structures that safeguard data integrity.
Before getting into the details of the normalisation process, you should be familiar with a few characteristics of attributes.
Atomic or composite?
In less formal data structures (including text files and spreadsheets) convenience is typically the main priority. That is the reason why a spreadsheet might contain a column called address. In a database, however, the principles of efficiency and re-usability are typically more important and the structure can be made more flexible by separating all of the components of the address into different columns (eg, street, area, town, postcode, region, country, etc.). This allows the database user to filter or sort records by these different components in ways that might not be important for the spreadsheet user. Because the address attribute contains a large value that can be split up further, it is called composite. In contrast, the set of attributes which contain only a single value which cannot be sub-divided are called atomic.
Single- or multiple-valued?
Another practice which is convenient in an informal structure is to place multiple values in a single attribute. This might happen for example if you had a spreadsheet for recording staff development activities: every time a staff member completed a training course it could be added to a list contained in a single column. With what you know about database relationships, you should be able to suggest an alternative to this whereby the staff members and training courses are held in separate tables, and a bridge table could be used to record which staff have completed which courses.
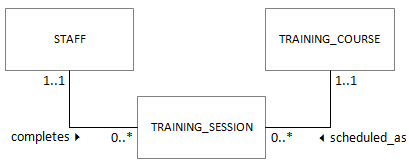
Clearly, single-valued attributes are preferable to multi-valued attributes when building database structures. Using multiple-valued attributes would mean that some queries would be impossible, and some details would therefore be inaccessible to the user.
Basic or derived?
Some useful pieces of data are the results of calculations such as the total on a bill (sum of all the items), or the duration of a journey (end time - start time). These are known as derived attributes. In general, only the basic values on which the calculation is based are stored as attributes in a database; derived values are calculated when they are needed.