First normal form
Normalisation proceeds through a series of refinement steps to arrive at a relational structure with the required properties. In the descriptions that follow, try to remember that normalisation is supposed to be a deterministic process with minimum reference to your own preconceptions about entities and relationships. Applied properly, you should find that you are deliberately ignoring certain facts that may be used in a later step. This is simply the nature of a rigorous process. It is always tempting to jump ahead; however, if you do that, you risk missing an important detail along the way.
We will be normalising the data to 3rd normal form. That will required going through three stages. At each stage there are some problems that you need to check for, and if you find them there are procedures for fixing them. Remember that problems must exist before you try to fix them - don't make any changes unless the problem situations are present.
The starting point for normalisation might be an unanalysed set of attributes that need to be split into separate relations with the appropriate relationships between them. This might be the case, for example, if you were automating an existing system based on paper records or spreadsheets. If the consultant and project data from the previous page were stored in a spreadsheet, for example, it might look like this:
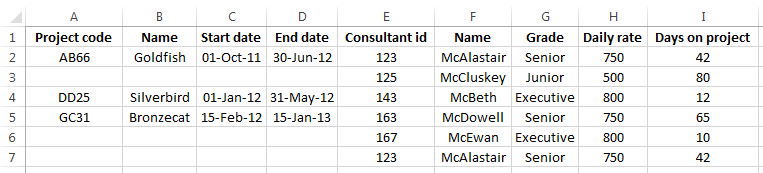
We already have a list of the attributes provided by the column headings, which is useful. Notice however that to improve presentation the owner of the spreadsheet has only listed the project details once, and then added additional rows for further consultants. Put another way, for every project record the fields consultant id, name, grade, daily rate and days on project may appear several times. This is an example of a repeating group of attributes which is important in the refinement of the model to first normal form (1NF).
NB. Before starting the normalisation process, you should check the characteristics of the attributes themselves: any composite attributes should be split up into their component parts, and any attributes that contain multiple values should be divided up into a series of identical attributes. In doing this you will create another type of repeating group of attributes that will be removed at 1NF.
First normal form
The official definition of 1NF is a relation in which there are no repeating groups. Since every relation should also have a primary key, there are three main requirements:
- There must be no multi-value or composite fields - ie all data must be atomic
- There must be no repeating groups of attributes
- There must be a primary key
The structure above could be written using the usual convention for a schema, but with brackets to indicate a repeating group:
cons_proj(proj_code, proj_name, start_date, end_date, (cons_id, cons_name, grade, daily_rate, days) )
There are two common ways to eliminate repeating groups. The first is simply to fill in the blanks left in the spreadsheet as shown below. This is called flattening the data since it removes the implict structure in the original spreadsheet.
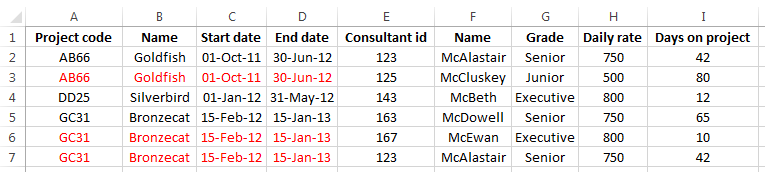
Once the blanks are filled in, we can think about an appropriate primary key. Examining the dependencies we find that the combination of cons_id and proj_code will uniquely identify a row and every other attribute is dependent on one or both of those attributes.
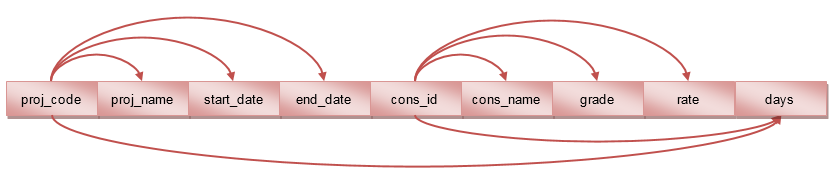
We can therefore write the structure like this:
cons_proj(proj_code, proj_name, start_date, end_date, cons_id, cons_name, grade, daily_rate, days)
This relation is now in 1NF.
The second method is to immediately remove the repeating group along with the original primary key into a new relation. Both methods eventually reach the same result; however, the second assumes that you have already identified a primary key. This is not always easy, and the first method might therefore be easier to apply. If you did split the attributes at this point, you would need to maintain the relationship by adding a foreign key. It is clear that one project is related to many consultants, so the resulting structure would look like this:
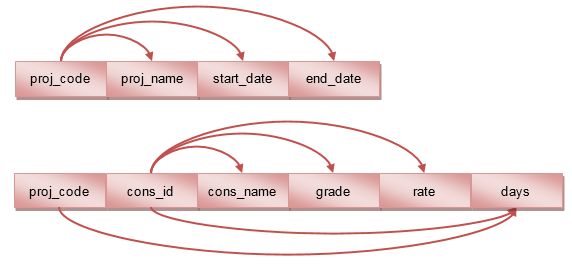
project(proj_code, proj_name, start_date, end_date) cons_proj(proj_code, cons_id, cons_name, grade, daily_rate, days)
This structure is also in 1NF. In the rest of the worked example, we will be assuming that the first method was used.