Comparison with SQL
Terminology
Conceptually, many of the terms already familiar from relational databases can be mapped onto equivalents in the NoSQL world. The following table illustrates this using the terminology employed by MongoDB, a document store.
| SQL terminology | MongoDB terminology |
|---|---|
| database | database |
| table | collection |
| row | document |
| column | field |
| index | index |
| table joins | embedded documents and linking |
| primary key | primary key |
Performance
Most NoSQL databases claim to have better performance than traditional relational systems. It is important to approach this sort of claim critically, however. NoSQL databases are designed to solve certain types of data management problem, and it is on those specific problems where performance tends to be the best. Simple inserts or updates based on the primary key, for example, tend to be very fast, but the traditional SQL approach performs better when more complex processing is required, or when accessing data based on non-key attributes.
The graphs below illustrate some of the performance differences observed between Microsoft SQL Server and MongoDB in a recent study (Parker et al, 2013). In their tests, the authors performed equivalent operations on the two databases on datasets of different sizes as shown in the following table..
| Test case | Departments | Users | Projects |
|---|---|---|---|
| 1 | 4 | 128 | 16 |
| 2 | 4 | 256 | 64 |
| 3 | 16 | 1024 | 512 |
| 4 | 128 | 4096 | 8192 |
Figs. 1 and 2 show the superior performance of MongDB for update operations that rely on key field, and the poorer performance when updates reply on a non-key field to locate documents/records. This difference in performance can be explained with reference to the design of the MongoDB data objects: key fields are indexed for fast searching, but because the document is unstructured, other attributes may or may not be present. This entails a lot of processing overhead for checking each document for the required value. In relational databases, however, the regular structure of each record support ad-hoc queries much better.
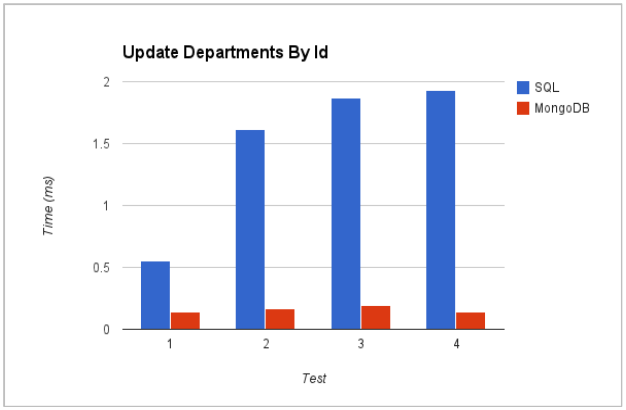 Fig. 1: Update using a key field
Fig. 1: Update using a key field
 Fig. 2: Update using a non-key field
Fig. 2: Update using a non-key field
Figs. 3 and 4 show the fast response of MongoDB to simple queries, but the superior performance of SQL on complex queries including aggregate functions. One reason for the good performance of MongoDB in the simple case is that it holds the whole dataset in memory whereas SQL will almost always have to retrieve data from disk. These experiments were conducted on small datasets which could fit easily into memory; to get a complete picture of the relative performance of the two platforms, similar tests would need to be done on datasets too large to fit into memory. In that situation MongoDB would also need to fetch data from disk and the performance might be more similar (Honours project, anyone?).
 Fig. 3: Simple select using a key field
Fig. 3: Simple select using a key field
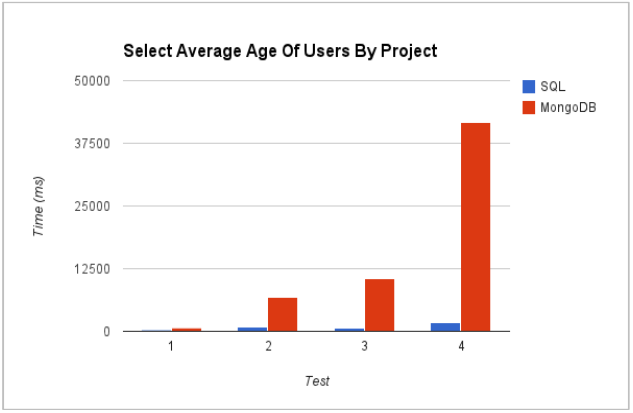 Fig. 4: Complex select including an aggregate function
Fig. 4: Complex select including an aggregate function
An obvious explanation for the good performance of SQL on aggregate functions is that relational database are designed for this type of operation while NoSQL databases are not. MongoDB includes the MapReduce operation, but it is slow in comparison to the optimised architecture of a relational database, and typically aggregate calculations would need to be done in application code.
Another point to remember when looking at results like this is that it is dangerous to draw general conculsions from one set of tests. The test conditions - including choice of database platforms, nature of the datasets, choice of operations, etc. - all have an effect on the results. It is not possible to say from these results that NoSQL database perform better than relational databases in generqal; it is not even possible to say that MongoDB performs better than SQL Server. A different set of tests would almost certainly show other disparities between the two. All we can say is that under certain circumstances, one platform will outperform the other and that care needs to be taken in the early stages of a development project to select the most appropriate database for the application.
 Comparing NoSQL MongoDB to an SQL DB
Comparing NoSQL MongoDB to an SQL DB Oracle NoSQL Database
Oracle NoSQL Database