Referential integrity
Apart from considerations of efficiency and performance, the job of the DBMS is to maintain various forms of data integrity which concerns the type of data stored in a column and any constraints that might apply such as a restricted range of values. Entity integrity is the requirement to be able to uniquely identify each individual entity which translates into the need for primary keys. Referential integrity is the requirement that the value of any foreign key field must identify a unique record in the related parent table. The set of primary key values in the parent table define the domain of the foreign key column in the child table.
If a foreign key value has no matching primary key in the parent table the data is inconsistent. The existence of a foreign key value suggests that a relationship exists, but if the related record cannot be found vital information may be missing about the child record. An example might be a club membership database as represented below. If the foreign key value on a member record did not correspond to a primary key in club, then there is no way to know which club the member belongs to.

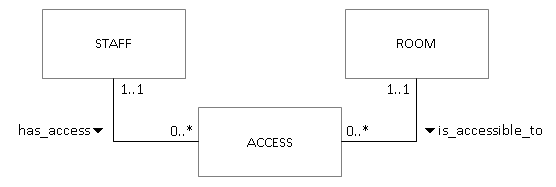
At the extreme, orphan foreign key values can introduce completely meaningless data into the database. Consider a bridge table which consists only of two foreign keys such as the one which links staff and room in a system which controls door access by means of swipe cards. It is likely that both staff_id and room_id will be synthetic keys. With no matching parent records, values in the bridge table are simply meaningless numbers.
Sanity checks
Data integrity is maintained by carefully designing the definition of a column at the point the table is created. This can go beyond just specifying a datatype by including programmatic rules called constraints which validate the data before it can be stored. Constraints will be discussed in more detail later in the module. The main point to note here is that the DBMS will prevent the user from storing any data which does not satisfy the criteria set of a particular column.
In a well-designed database, every table should have an appropriate primary key defined. In certain cases, a database may still behave as expected if one or two tables do not adhere to this rule, but in general leaving out primary keys is bad practice and can cause data anomalies which will be discussed later in the module. One practical implication of defining primary keys is that the DBMS will not allow the user to store a record unless a) the primary key field has a value and b) that value does not appear on any other record.
The relationships between entities are represented in the database by foreign key constraints. Really, this just means that when a child table is created one (or more) columns are defined as the foreign key and in addition, the related parent table is also specified. In effect, this means that the value in the foreign key field of the child table is the same as the value in the primary key field in the parent table - ie the values match. Referential integrity is the requirement that the corresponding parent record MUST exist for a foreign key value. If this rule were not enforced, it would be possible to have meaningless data stored in the database, either in the form of child records with no parent or foreign key values with no referential target.
Again, as in the case of other types of integrity, the DBMS will prevent the user from doing certain operations which would cause a loss of referential integrity. In particular:
- A child record cannot be inserted with an unknown foreign key value - ie one that does not exist as a primary key in the parent table
- A parent record cannot be deleted while related child records still exist
- A primary key value cannot be updated while related child records exist (although, this situation should never actually arise)
These rules have practical implication for data maintenance. For example, when inserting a set of data into a pair of related tables, each parent record must be inserted before the child records. Otherwise you are trying to insert a foreign key value before it exists as a primary key value in the parent table. Likewise if you are deleting a set of data, child records must be deleted before related parent records.
Data maintenance
There may be genuine reasons for deleting a parent record from the database. If that situation arises, there are essentially two options:
- Insist that the user deletes any related child records before attempting to delete the parent record
- Automatically delete any related child records when the parent record is deleted.
The first case is usually the default and in that situation an attempt to delete the parent record would result in an error message if related child records exist. However, an application designer can decide to manage the deletion of child records with application code which explicitly goes through any related records and applies appropriate conditions to determine whether or not to delete them automatically. This allows for complex situations and fine-grained record handling compared to embedding this behaviour in the database definition.
Automatic deletion of child records is know as cascading the delete operation. As part of the database definition, the cascade behaviour can be specified in the CREATE TABLE statement:
1 2 3 4 | |
Notice that the cascade behaviour is part of the definition of the foreign key constraint, and therefore attached to the child table. The definition above means that if a parent staff or room record is deleted, any related records in access are also deleted automatically.
Clearly, whether or not to include automatic deletion of child records in the database requires careful consideration. The deletion of child records will happen without any warning to the user, and so if there are situations in which that should not happen, the better option is to handle those cases explicitly with application code.