Describing schemas
A realistic schema for a large database system can include hundreds of tables. Once it reaches that size, getting all of the tables onto a single ER diagram is no longer feasible. One alternative is to break the diagram down into smaller parts, but even then the problem is not solved completely. A better solution is to have a way of expressing the same information in a much more condensed form.
Although there are no recognised standards for expressing schema contents in text-only form, there are some common conventions which it is important to know.
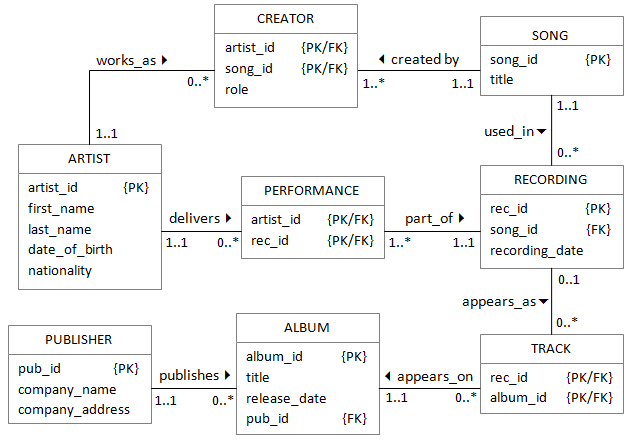
A schema is basically a list of relations (tables) and their attributes (columns). We could therefore represent the simple schema in the diagram above like this:
artist(artist_id, first_name, last_name, data_of_birth, nationality)
creator(artist_id, song_id, role)
song(song_id, title)
performance(artist_id, rec_id)
recording(rec_id, song_id, recording_date)
track(rec_id, album_id)
album(album_id, title, release_date, pub_id)
publisher(pub_id, company_name, company_address)
In this list, a relation's attributes appear inside the brackets following the relation name. The primary key is shown underlined, and a foreign key is shown in italic.
You might think that the information about relationships is greatly reduced in the text version. In fact, you can reconstruct the ER diagram almost entirely by using the foreign keys. For example, the CREATION relation has two foreign keys which are also primary keys. This immediately suggests that the table is a link table which resolves a many-to-many relationship. One of those foreign keys has the same name as the primary key in the ARTIST table which shows where the first relationship is. The second links to the SONG relation. The location of the foreign key identifies the "many" end of each of the relationships and confirms what we thought at the beginning about the nature of the CREATOR relation.
We could go through the whole schema like this and reconstruct most of the information in the diagram. The only thing that would be lost in this case would be the relationship labels. Actually, there are some other types of information that could be lost in this format. One-to-one relationships would be difficult to identify, for example, as would relationships where the foreign key has a different name from its corresponding primary key. These can only be reconstructed by reference to the semantics of the names - that is to say, their meaning. This illustrates how it is important to choose meaningful names for your relations and attributes.
Despite these small drawbacks, this way of describing a schema is very compact and has sufficient information for reasonably experienced database users.