NoSQL databases
Relational databases were designed with optimal efficiency in mind and over the last 40 years the technology has simply got better and better. However, the huge growth of unstructured and semi-structured data is testing the limits of the model and a number of alternative architectures are now available. Before abandoning the relational model for something new and shiny, however, it is important to know a little about the alternatives and their advantages and disadvantages.
The general term for the range of new architectures is NoSQL. This is not a suggestion that SQL is no longer relevant and the generally accepted interpretation of the name is that it means Not Only SQL. The implication is that the selection of database platform depends on the context of use and that the relational model is still the best choice in certain cases.
Types of NoSQL database
The top link on the right will take you to a page which lists around 150 different databases which fall under the NoSQL heading. There is no one single architectural model, but there are four main categories summarised in the table below. Further description is provided by Moniruzzaman & Hussain (2013).
| Type | Description |
|---|---|
| Key-Value stores | The main goal is to scale to very large data sets while providing acceptable performance. The model is a global collection of key-value pairs based on deCandia's 2007 paper for Amazon. A key-value store reduces the complexity of the data structure to the minimum. Queries can be performed against keys but not against any part of the associated values. Only exact matches are supported to maintain high performance. |
| Column stores | As with key-value stores, the goals are scalability and speed but the data is assumed to be more structured. This model is based on the work by Chang et al. (2008) on Google's BigTable storage system. The model is similar to the relational model in that it can be visualised as a grid, but a major difference is that column stores are designed to be distributed to allow parallelisation of queries. Operations rely heavily on the MapReduce framework described below. |
| Document stores | Designed for convenient storage of unstructured and semi-structured data using common object notations such as JavaScript Object Notation (JSON), document stores integrate very well with Web applications. Document stores provide a combination of indexed keys for fast retrieval and semi-structured values which can also be addressed by queries. They therefore represent a compromise between the structured data in a relational database and the stripped-down and limited structure of a key-value store. |
| Graph stores | Based on mathematical graph theory, graph stores represent data as a set of key-value pairs (nodes) which are connected explicitly by relationships (edges). The main goal of the model is not performance but the convenient visual representation of relationships between objects. |
Scalability
Part of the reason for the growing interest in new database models comes from the need to handle very large datasets. Relational databases still provide superior performance in transactional systems where the quantities of data are relatively low. However, they are essentially designed to run on a single machine, and the only way they can be scaled to cope with higher processing demands is to use a higher-specification machine - ie. one with faster processors, more processor cores, more memory, higher-throughput drives, etc. This is known as vertical scaling. NoSQL database, in contrast, are designed for horizontal scaling in which the processing load can be spread across more machines. This model has several advantages for cost and reliability. The computers on which the database runs can be low-cost commodity machines rather than the specialist, high-specification machines required for an equivalent relational database. Also, if one of those machines fails for some reason, processing can continue on the rest. A further advantage of the distributed model is that it works well with virtual cloud-based resources. In an environment such as Amazon's commodity cloud infrastructure, new virtual machines can be added to a cluster as the processing load increases.
Some NoSQL databases directly implement a well-known model for parallel processing called MapReduce. While not the only approach, MapReduce provides a good example of how a complex processing operation can be efficiently split over a cluster of processors:
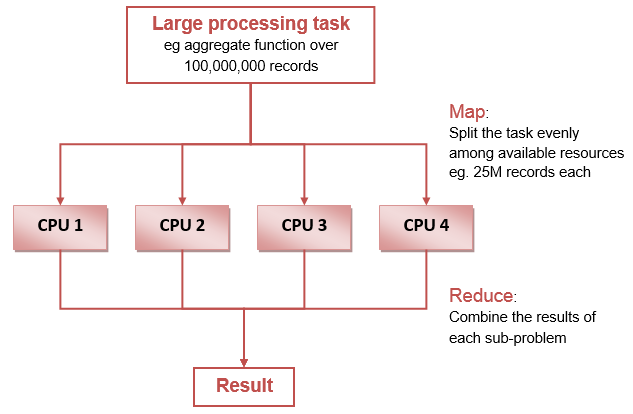
NoSQL databases typically include another approach to horizontal scaling called sharding. In contrast to MapReduce, sharding involves splitting the data into subsets according to some data value. A set of student data, for example, might be split into 100 shards using the matriculation number by dividing the range of values into 100 roughly equal sets. A query based on matriculation number would then only be run on the relevant shard, thus reducing the total amount of processing required. Sharding reduces the search space in a similar way to the indexes found in traditional relational databases.
Further reading
 NoSQL Database: New Era of Databases for Big data Analytics
NoSQL Database: New Era of Databases for Big data Analytics