Keys
One of the main purposes of a database is to be able to find the information you need as quickly as possible. This requirement leads to the seemingly trivial observation that it must be possible to uniquely identify a specific row in a table. However, this is not always as easy as it sounds. For example, given a group of four people like the employees in our imaginary company, how might we uniquely identify them?
| employee | office | extension |
|---|---|---|
| Pete | 1 | 2001 |
| Quincy | 3 | 2003 |
| Rachel | 2 | 2002 |
| Shonagh | 4 | 2004 |
Using their names might be a good method. However, if our group was 4,000,000 instead of just four, would the name method still work? The chance of several people having the same name in a group that size is quite high, and therefore we need some other method for finding specific individuals.
In the relational model, a key is an attribute or group of attributes whose values can be used to uniquely identify a row. The concept of a key is quite easy to grasp since there are many everyday examples. Telephone numbers act as keys by identifying one and only one fixed line or mobile SIM card. You use these keys without realising every time you make a telephone call. A key is simply a piece of data that can be used to look up other data reliably. When someone calls you, the network users the telephone number to find any other information it needs about you to connect the cal.
When we have a key such as a telephone number which can be used to look up a set of further attributes from the same row in a database table, we say that the key attribute functionally determines the other attributes. In other words, if you can look up, say, the network using the number, then the number determines the network. Notice that this relationship is not reversible: knowing the network does not enable you to look up the number - there will be many numbers on the same network. Instead, we say that the network is functionally dependent on the number. You will need these concepts in week 6 when we look at normalisation.
Say that our company needed to employ a new member of staff, and that the new person has to share a room. Coincidentally, the new employee's name is Pete:
| employee | office | extension |
|---|---|---|
| Pete | 1 | 2001 |
| Quincy | 3 | 2003 |
| Rachel | 2 | 2002 |
| Shonagh | 4 | 2004 |
| Pete | 4 | 2004 |
Looking at the table, there is clearly no single attribute that can be used to identify each row uniquely. However, we could use the combined values of the employee and office attributes. This is perfectly acceptable in the relational model, and a key that includes more than one attribute is known as a composite key.
In fact, it is likely that the EMPLOYEE table would also include other data such as last name and national insurance number as shown below:
| first_name | last_name | date_of_birth | ni_number | office | extension |
|---|---|---|---|---|---|
| Pete | Brown | 16/4/1964 | 12435 B6934C | 1 | 2001 |
| Quincy | Green | 12/11/1974 | 23412 D6274C | 3 | 2003 |
| Rachel | White | 15/2/1985 | 34253 F6351B | 2 | 2002 |
| Shonagh | Brown | 20/7/1969 | 23415 K3652A | 4 | 2004 |
| Terry | Black | 12/11/1974 | 31243 W2784D | 4 | 2004 |
Now there are actually many keys that we could use to uniquely identify a row. The national insurance number is guaranteed to be unique for each individual, so it is a natural key. There are also many possible composite keys - the list below shows the options:
- ni_number
- ni_number, last_name
- date_of_birth, office, first_name
- first_name, last_name, date_of_birth
- first_name, last_name, date_of_birth, extension
Most of the options contain redundant attributes - they specify more data than is necessary to identify one row. For example, last_name is redundant in option 2 because ni_number is already enough to uniquely identify a row. Any attribute or combination of attributes that can be used to uniquely identify a row is known as a superkey. A superkey which contains no redundant attributes is known as a candidate key. It is then up to the database designer to select one of the candidate keys as the one that will be recognised in the database as the proper way to identify rows in the table. The final selection is known as the primary key for the table, and is one of the most important elements of relational database design. The existence of a primary key guarantees a property called entity integrity which means that every individual entity in a set can be uniquely identified. The diagram below summarises the different types of key:
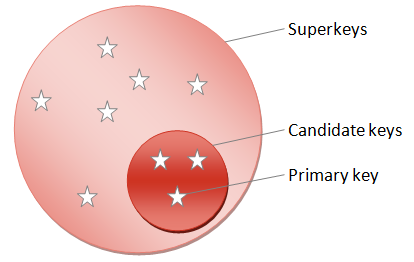
NB. Sometimes it may not be possible to find a single attribute or group of attributes that uniquely identify an entity. The only solution in that case is to introduce a unique id number. This is known as a synthetic key, and all reputable relational database platforms have ways to let you generate unique numbers. It may be tempting to add a synthetic key to every table, but that may lead to errors in normalisation. In general, you should only use synthetic keys if
- There is no viable group of attributes that can be used as a primary key
- There is a potential candidate key, but its value may change over time
- There is currently a good candidate key, but future records may have the same value
- The only viable candidate key is composite and includes a date value - dates are difficult to use and can lead to query errors
- The only viable candidate key is a composite key with several components - a synthetic key may be used for convenience to simplify joins